Google发布Gemini 2.5 Flash Image: 革命性图像生成和编辑模型
2025年8月26日 今日,Google正式推出了其最新的AI图像生成和编辑模型——Gemini 2.5 Flash Image(内部代号"nano-banana"),这是一款具有突破性功能的图像AI模型,为开发者和企业用户带来了前所未有的创意控制能力。

测试声明: 文中展示的动图和静态图片均经过压缩处理,存在色彩失真或细节损失;实际测试效果可能因提示词表述、输入图片质量、模型版本等因素而有所差异。本测试结果仅供参考,不代表模型在所有场景下的表现。
🚀 核心功能亮点
1. 角色一致性维护
解决了图像生成领域的核心难题——在多个提示和编辑中保持角色或物体的外观一致性。用户可以:
- 将同一角色置于不同环境中
- 从多个角度展示单一产品
- 生成一致的品牌资产

2. 基于提示的智能图像编辑
通过自然语言实现精确的局部编辑,包括:
- 背景模糊处理
- 去除衣物污渍
- 从照片中移除人物
- 改变主体姿态
- 为黑白照片上色
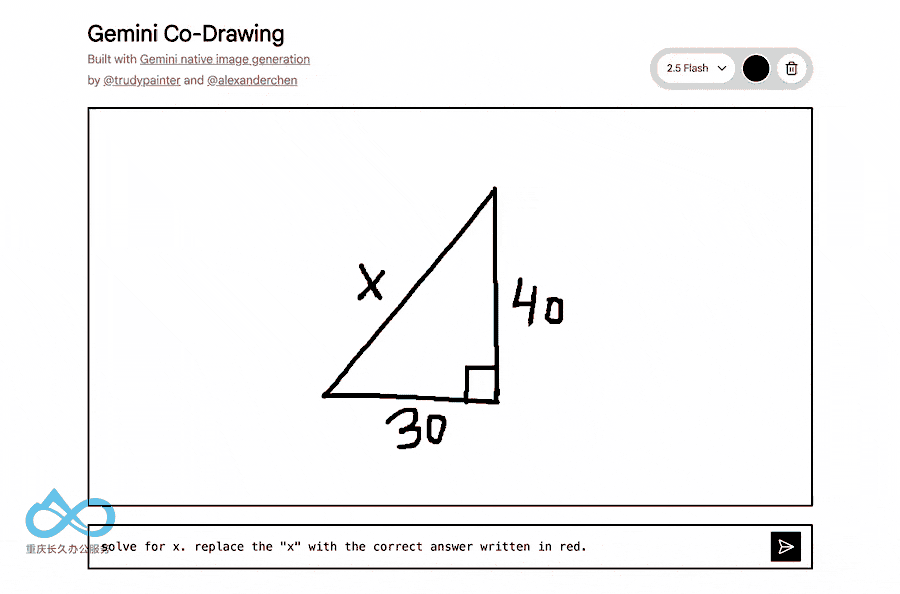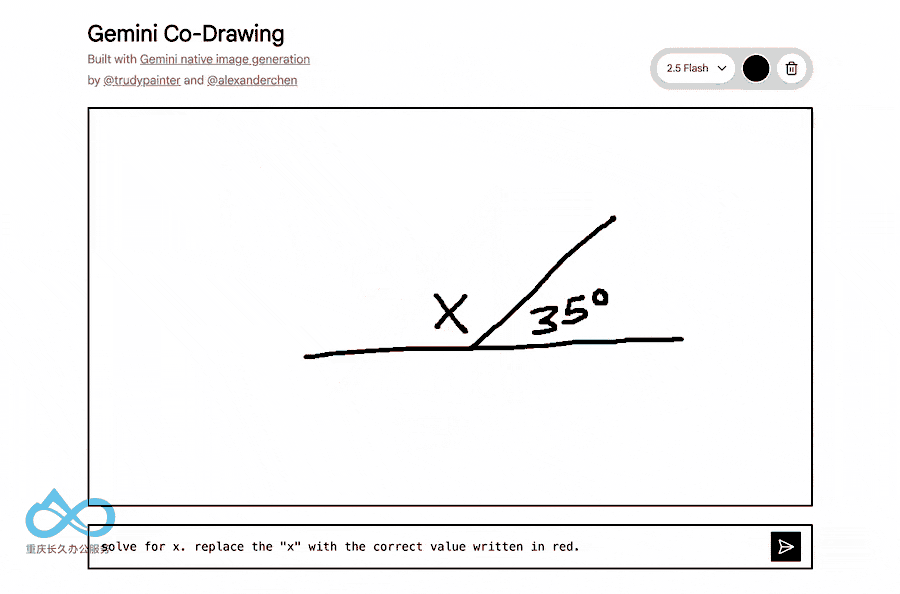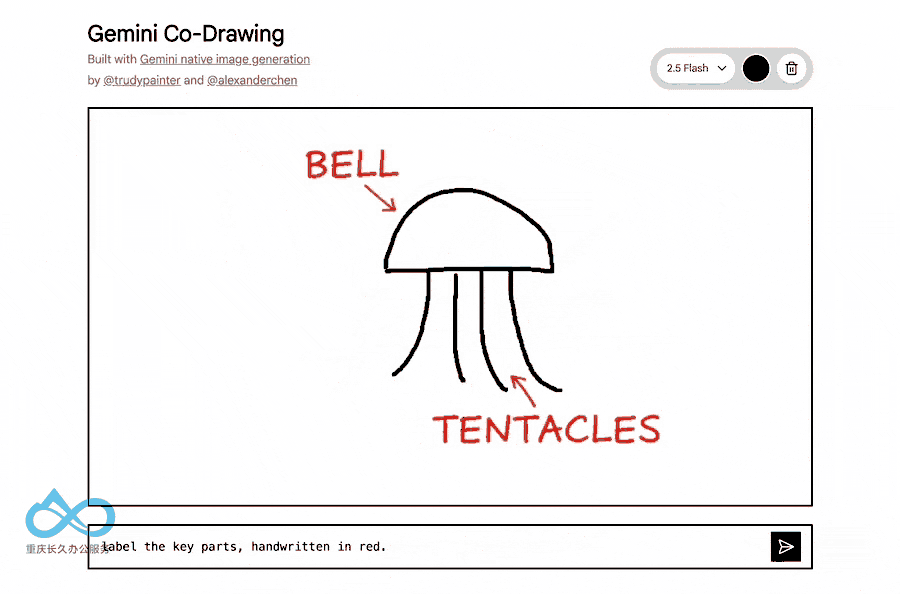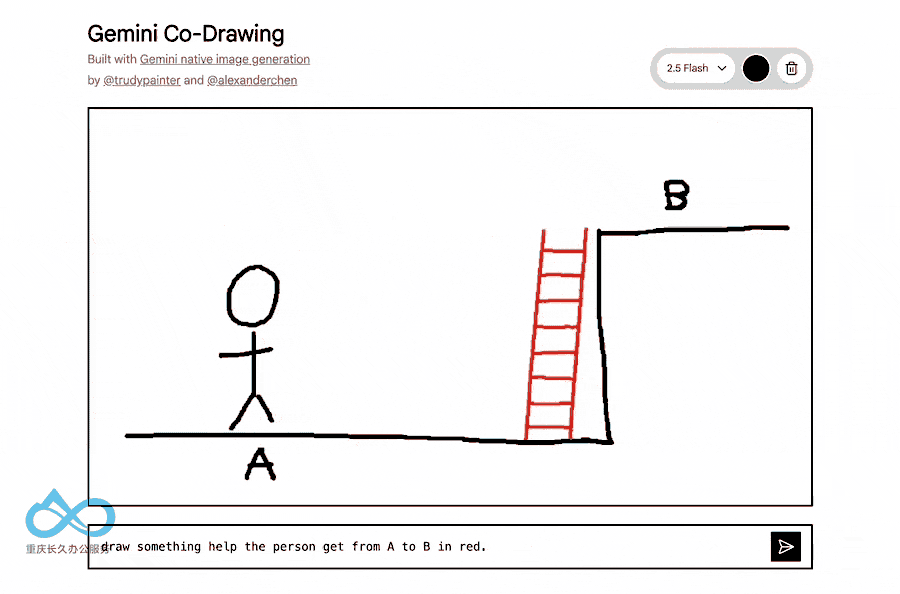
3. 原生世界知识集成
与传统图像生成模型不同,Gemini 2.5 Flash Image融合了Gemini的世界知识,能够:
- 理解手绘图表
- 回答现实世界问题
- 执行复杂的编辑指令
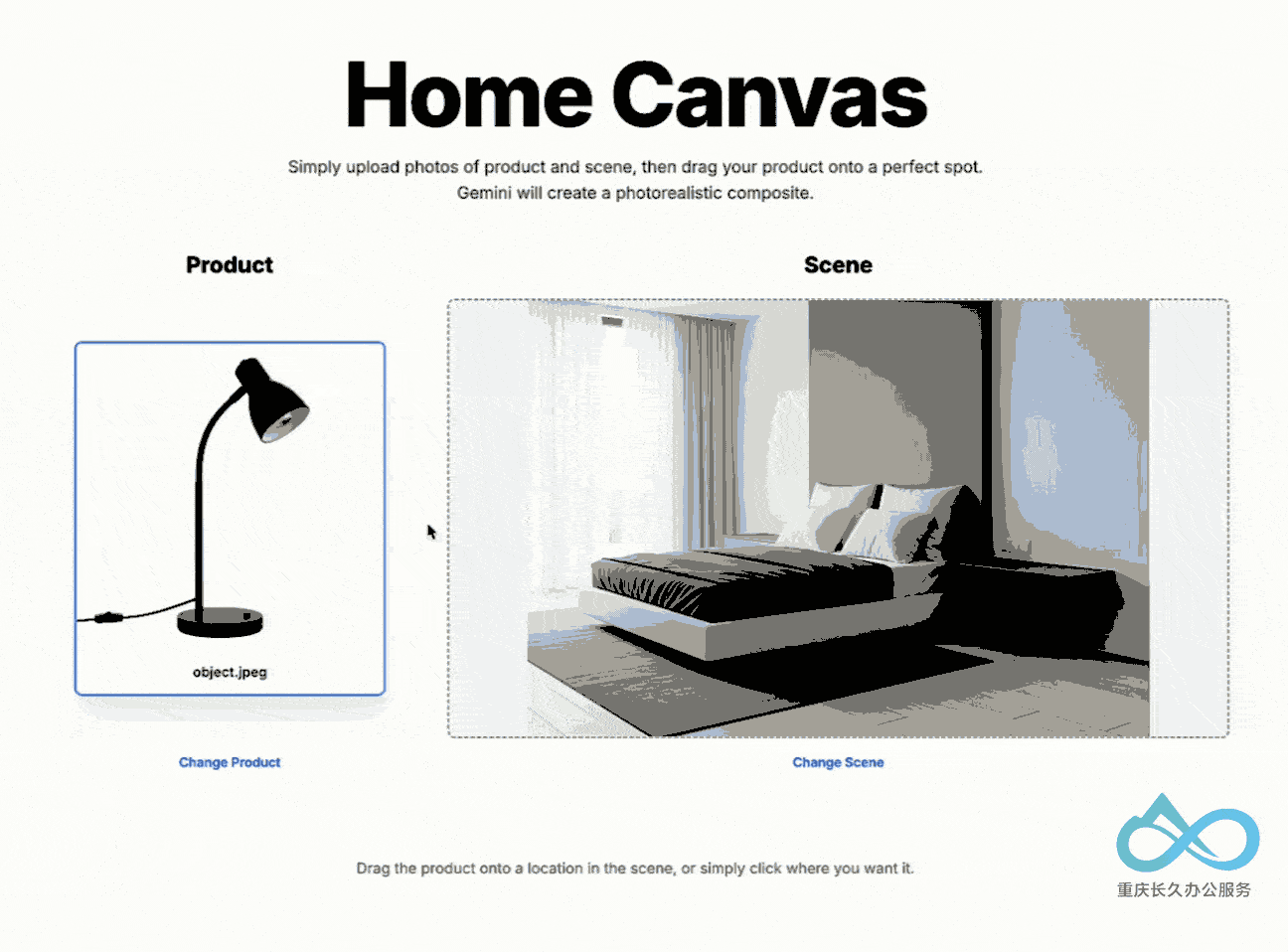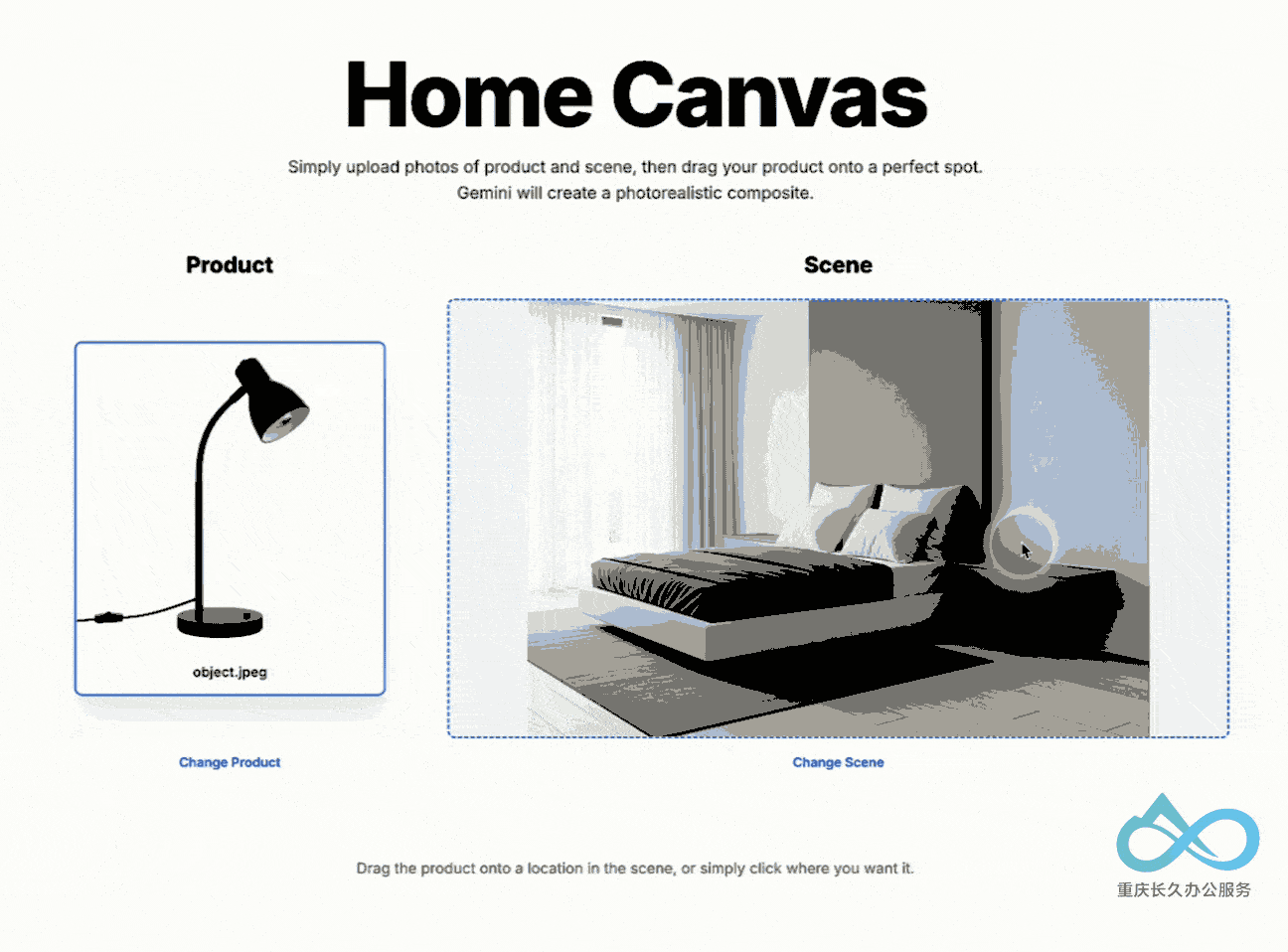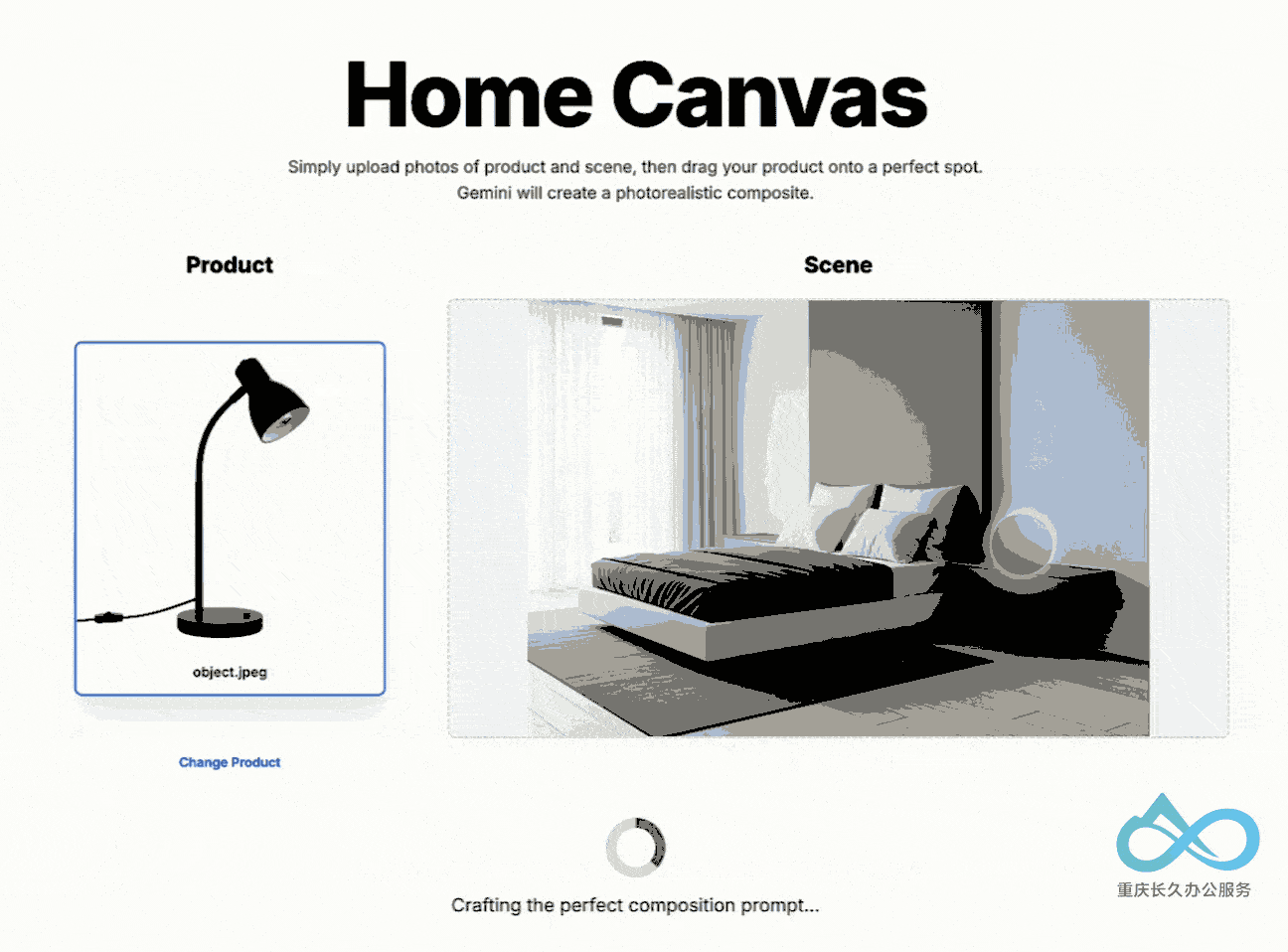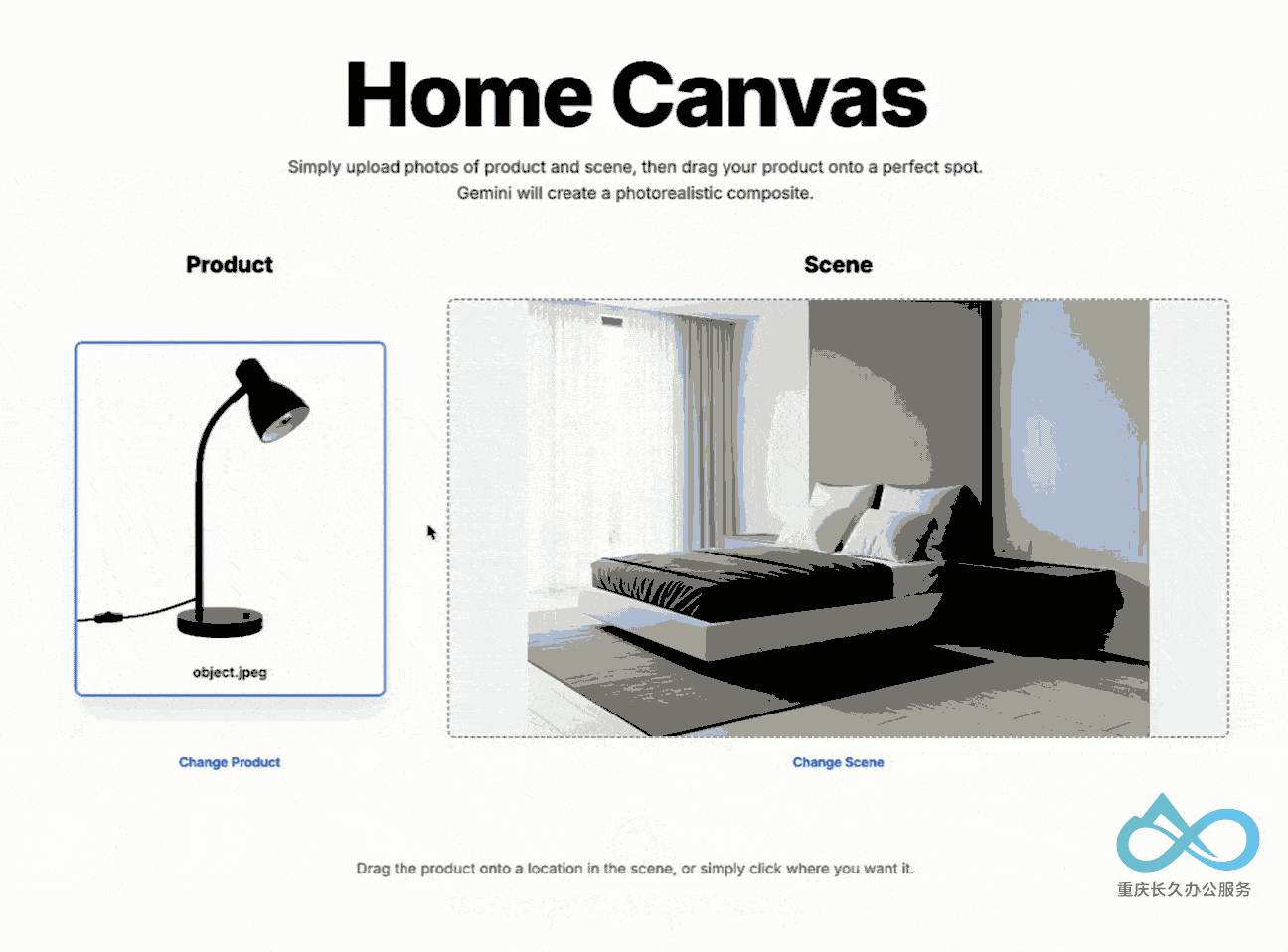
4. 多图像融合技术
支持理解和合并多个输入图像:
- 将物体放入新场景
- 用特定配色方案重新设计房间
- 单一提示融合多张图像
🧪 实际测试体验
为了验证Gemini 2.5 Flash Image的实际表现,我们进行了几项测试:
测试1:科技主题海报生成
我们尝试生成Gemini 2.5 Flash Image的宣传海报,包含中英文标题。
提示词(英文):
"A sleek tech announcement banner with 3:2 aspect ratio, Google Gemini logo prominently featured, 'Google releases Gemini 2.5 Flash Image' in bold white text at top, subtitle 'a revolutionary AI image generation and editing model' below..."

提示词(中文):
"现代科技风格的社交媒体头图,3:2比例,Google Gemini 2.5 Flash标志居中显著展示,顶部有'Google Gemini 2.5 Flash Image发布'的现代粗体中文标题..."

测试2:多图像融合挑战
我们尝试将人物照片与风景照片进行融合。
输入材料:
- 人物自拍照(非真实人物)

人物自拍照 - 重庆洪崖洞夜景照片

提示词(英文):
Create a realistic photo composition showing the person from the first image standing in front of the Hongya Cave and Jiefangbei (Liberation Monument) nightscape from the second image. The person should appear to be taking a selfie or posing for a photo with the iconic Chongqing landmarks in the background.
Technical requirements:
- Seamlessly blend the person into the nighttime cityscape
- Match the lighting and color temperature of the night scene
- The person should have natural lighting that reflects the ambient glow from the buildings
- Position the person in the foreground as if they're a tourist taking photos
- Maintain realistic proportions and perspective
- Preserve the vibrant neon lights and architectural details of Hongya Cave
- Ensure the overall composition looks like a genuine travel photo
Style: Photorealistic, travel photography, natural pose, nighttime urban setting
融合结果: 
📊 性能表现
根据LMArena的评测结果,Gemini 2.5 Flash Image在图像编辑能力方面表现卓越,超越了多个竞品模型。
💰 定价策略
价格:每100万输出tokens收费30.00美元
- 每张图像等于1290个输出tokens
- 单张图像生成成本约0.039美元
- 其他输入输出模态遵循Gemini 2.5 Flash标准定价
🛠️ 开发者支持
可用平台
- Gemini API:面向开发者
- Google AI Studio:提供可视化开发环境
- Vertex AI:企业级解决方案
合作伙伴
- OpenRouter.ai:为其300万+开发者提供服务,这是该平台480+模型中首个支持图像生成的模型
- fal.ai:领先的生成媒体开发平台
代码示例
=
=
=
=
is not None:
=
🔒 安全保障
所有通过Gemini 2.5 Flash Image创建或编辑的图像都将包含不可见的SynthID数字水印,确保AI生成或编辑的内容可以被识别和追踪。
🌟 行业影响
Gemini 2.5 Flash Image的发布标志着AI图像生成技术进入了新的发展阶段,其独特的多模态融合能力和世界知识集成,为创意产业、教育领域和企业应用开辟了全新的可能性。
该模型目前处于预览阶段,预计在未来几周内将发布稳定版本。开发者可以通过Google AI Studio的模板应用快速体验和定制功能,所有演示应用都支持一键重构和自定义。
想要了解更多信息或开始构建应用?访问Google AI Studio或查看开发者文档。
原文出处: Introducing Gemini 2.5 Flash Image, our state-of-the-art image model





